Pakko De La Torre // Represented by ATRBUTE Worldwide
Sustainability | Free Full-Text | Intelligent Damage Assessment for Post-Earthquake Buildings Using Computer Vision and Augmented Reality
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
As one of the most destructive disasters, earthquakes occur more than one million times a year. A large number of people are exposed to the risks or hazards caused by earthquakes every year [1,2]. Taking the year 2021 only as an example, there were 115 earthquakes of magnitude 6 or higher around the world, of which 19 are earthquakes of magnitude 7 or higher. The most direct hazard caused by earthquakes is the damage or collapse of buildings, which results in substantial personnel casualties and property losses [3]. After an earthquake, both structural and non-structural elements of buildings will be subject to varying degrees and forms of damage. Therefore, a damage assessment based on information about the destruction that occurred is an important prerequisite for post-earthquake reinforcement and repair. Reliable assessment results can not only provide references and guidance for the sustainable reinforcement and repair of post-earthquake buildings but also assist in the timely development of a sound rescue plan [4].
The contributions of this paper can be mainly concluded with three points: (1) Propose an intelligent damage assessment method that integrates CV and AR to realize an intelligent damage assessment. (2) Establish the transformation relationship from 3D coordinates to 2D image coordinates and 2D pixel coordinates, which supplies quantity information for a damage assessment. (3) As an innovative means of information collection, apply AR in the damage assessment of a post-earthquake building.
With the development of information technology, especially the widely used UAV (Unmanned Aerial Vehicle) and 3D scanning of earthquake sites [20,21], damage assessments have also tended to become more intelligent. Wang et al. [22] studied pavement crack detection techniques, and they found many problems in visual inspection and semi-automatic inspection. For example, the traditional inspection methods require far more manpower, material, and time resources than are practical. Furthermore, the speed and accuracy of detection are also difficult to estimate. In this research, Wang et al. conducted a study of the literature on crack image acquisition and crack image segmentation. The study compared the detection speed and accuracy of 12 algorithms for different crack images, which aimed to provide a reference for realizing the efficient and automatic detection of pavement cracks. Shakya et al. [23] conducted a visual inspection of damaged buildings in Bhaktapur after the Gorkha (Nepal) earthquake. However, considering the impact on specialist safety due to aftershocks and road damage, they had to interrupt inspections several times.
CNNs are one of the most representative deep learning algorithms, which has significant advantages for damage recognition [28]. CNNs can not only extract features automatically but also have a strong self-learning capability. In addition, CNNs can be used for both binary classification and multi-classification [29,30]. Cha et al. [31] conducted crack classification experiments on multiple photographs using CNN with an accuracy of 97.42%. Botta et al. [32] took 468 eggshell photos and then developed a dataset of image patches. They used a CNN and SVM to classify the image patches into “Crack” and “Intact” datasets. The experimental data collected by Botta et al. showed that the CNN model had an accuracy rate of 95.38% in eggshell image classification, which performed better than the SVM model. Bai et al. [33] proposed a method for optimizing the inspection of railway fasteners. This method used a modified Faster R-CNN (Region-Convolutional Neural Network) to recognize four different types of fasteners. The results showed that Faster R-CNN performed well in multi-classification. These studies mentioned above illustrate that CNNs can not only solve multi-classification problems but also have high classification accuracy.
3. The Fusion Mechanism of CV and AR in an Intelligent Damage Assessment
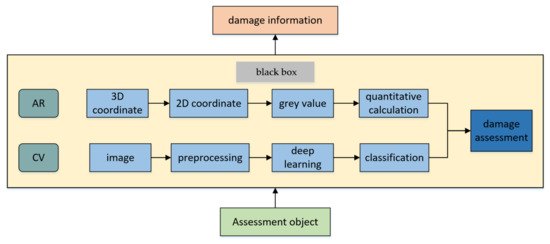
The information obtained from earthquake site sensors (such as UAV) will input images into the ‘black box’ for image recognition. AR can supplement virtual data, which is called AR data. In addition, AR data does not exist in the physical world. The main purpose of AR data is to supply the original data for coordinate transformation between 2D and 3D, which aims to obtain the quantity information for a damage assessment. After receiving the sensor information, the AR data are analyzed and processed in the ‘black box’. At this time, the quantity information and type information are all in the ‘black box’, waiting to be used in a damage assessment. Finally, AR can visually display the results of a damage assessment. The intelligent assessment method proposed in this paper is to analyze the information simply twice. First, the image and shooting distance information are analyzed for image recognition and grey value calculation. Second, the fused information, including the results of the image recognition and grey value calculation, is analyzed for the damage assessment. At the same time, the real-time dynamic damage assessment of seismic damaged components in post-earthquake buildings is completed, and the results of the assessment are ready for visual display.
The proposed method in this paper uses AR to dynamically enhance virtual data with 3D information, including shooting distance, into the real world. Then, the AR data and images are input into a ‘black box’ to obtain the fusion data (the detailed type of damage information and quantitative damage information). Moreover, the results of the damage assessment are expressed as damage classes by comparing the fusion data with damage assessment regulations. The damage information can also be visually displayed in the AR terminal. The fusion mechanism of CV and AR in the damage assessment is shown in Figure 2.
The coordinates of the virtual world are determined by the position of the virtual object in the real world so that both the coordinates of the real world and the coordinates of the virtual world are known. The main transformation relations of the three coordinates are as follows:
where is the real-world coordinate, is the virtual world coordinate, and is the transformation relationship between the real-world coordinate system and the virtual world coordinate.
where is the camera space coordinate; is the orthogonal identity matrix, which indicates the direction of the camera in the real-world coordinate; is a 3D vector, which indicates the position of the camera in the real-world coordinate; and is the transformation relationship between the camera space coordinate and the real-world coordinate.
The transformation relationship between the real-world coordinate and the virtual world coordinate is known, which means is known. Thus, obtaining is the key to realizing coordinated transformation. is a transformation matrix, which means can be converted into a combination of a rotation matrix and a translation matrix . The specific matrix conversion combination is shown in Equation (3).
The corrosion calculation of the non-flat structural element on the image at the position is:
The expansion calculation of the structural element on the image at the position is:
If all the elements of are constant, the above formula can be simplified as:
The transformation of the camera coordinates to the image coordinates is the transformation from 3D to 2D, as shown in Figure 5:
As shown in Figure 6, to establish the transformation relationship between an image coordinate and pixel coordinate, the variational sizes in the pixel are expressed as and :
The core of intelligent damage assessment based on CV and AR is to perceive information in real time and respond according to the target task [43]. According to research and practical experience in the literature [44,45,46], this paper selected the CNN as the deep learning algorithm to complete intelligent damage assessment.
The Sigmoid function, a commonly used activation function in CNNs, is often used for classification. This paper also uses the Sigmoid function as the activation function. To judge the robustness and generalization ability of the CNN model in this study, two parameters, i.e., the accuracy rate and the loss function, are introduced as evaluation indicators [32]. The definition matrix of each evaluation indicator is shown in Table 2, and the definition formula is as follows:
where is the label of sample , 1 for TP and 0 for FN and is the probability that sample is TP.
A complete CNN image recognition process includes image segmentation and data augmentation. The segmented image is called a patch. After filtering and data enhancement, a total of 4980 patches are available. 227 × 27 is the pixel size of the patches. After image segmentation, when the pixel size of the patches is 227 × 227, the damage state can be recognized well, and after reviewing the literature, our team found that a patch of this size is often used as the size for CNN recognition. If the pixel size is smaller than 227 × 227, the damage state can still be recognized well, but it will waste more manpower and time.
The authors collected 253 images with pixels 4032 × 3024 in the earthquake simulation laboratory to perform image recognition. After image augmentation, 4980 patches (227 × 227) were finally available for damage assessment [48]. According to the different crack widths, these 4980 images were divided into three databases: 01 (ω ≤ 0.5 mm), 02 (0.5 < ω > 2 mm), and 03 (ω ≥ 2 mm). The images were used to recognize the state of concrete and cracks. The training set and test set were classified according to the ratio of 2:1. The statistical information about the dataset is shown in Table 3.
The information on shooting distance and images of the damaged RC beams collected using the above system would be transferred to a computer terminal. For the visual display method of damage components and damage information, our team has already carried out many studies, and this paper applied the method of BIM-AR to display the damage model and damage information. The visual damage components and damage information are displayed with a computer, as shown in Figure 16. All the damage information including assessment results, damage models, and retrofitting methods were visually displayed using the AR platform (Augin®), as shown in Figure 17. The expression of the damage assessment comes from the specification ’Building Structural Drawing Standards’ [51]. The expression of the damage information comes from a set of coding rules [16].
After assessment of the crack width, crack type, and concrete fracture condition of RC beams, the results showed that the damage class of the component was C.
The rapid development of CV and AR has provided more scientific, effective, and visual ideas for the damage assessment of post-earthquake buildings. The IDEFO (Icam Definition Method) of the intelligent assessment method is shown in Figure 18.
This paper provided information on the fusion mechanism of CV and AR. The fusion of CV and AR not only enriches the diversity of post-earthquake building information but also realizes a closed loop of information generated during the assessment process.
The aim of the damage assessment method for earthquake-damaged buildings is to classify different damage states into different classes. CNNs and grey values are used to analyze and process the original data. The CNN is used for image recognition, and the grey value is used to calculate the quantitative information. CNNs and grey values can not only ensure the accuracy of classification but can also prevent the problem of overfitting.
Finally, the current research on the damage assessment of post-earthquake buildings is still insufficient. Further improvement in the science of damage assessment and data management remains a priority for future research. Next, our team will work to integrate damage assessment and damage information visualization. In the future, we will continue to dynamically link and visualize damage assessment information with building design information and reinforcement method information. Then, we will try to promote the intelligence, digitization, and visualization of repair and retrofitting methods of post-earthquake buildings.
Liu, Zhansheng, Jie Xue, Naiqiang Wang, Wenyan Bai, and Yanchi Mo. 2023. “Intelligent Damage Assessment for Post-Earthquake Buildings Using Computer Vision and Augmented Reality” Sustainability 15, no. 6: 5591.
https://doi.org/10.3390/su15065591